
_Summary
What is an accuracy rate in AI?
Let us start with the basics, because accuracy rate is one of those terms that everyone uses and almost nobody defines clearly when it comes to AI. In simple terms, the accuracy rate of an AI system is the percentage of outputs it produces that are factually correct. If you ask an AI to extract 100 figures from a regulatory document and 87 of them are right, its accuracy rate on that task is 87%.
The AI research community has been working hard to measure this precisely, and the results are more sobering than most enterprise AI marketing suggests. In December 2025, Google DeepMind and Google Research published the FACTS Leaderboard, one of the most comprehensive benchmarks ever developed for evaluating LLM factual accuracy. It tested leading AI models across four distinct dimensions of factual correctness, covering thousands of real-world examples. The finding: even the best-performing models get facts wrong roughly one time in three when working on complex, document-grounded tasks. (Source: The FACTS Leaderboard: A Comprehensive Benchmark for Large Language Model Factuality, Google DeepMind and Google Research, December 2025: deepmind.google)
The researchers were direct about the implications: “Large language models are transforming how we access information, yet their grip on factual accuracy remains imperfect. They can hallucinate false information, particularly when given complex inputs.”
This is the baseline for general-purpose AI, on general tasks. In specialised, high-stakes regulatory environments, the performance gap widens significantly. The EU AI Act already recognises this, requiring in Article 6 that high-risk AI systems — a category that explicitly includes AI used in credit scoring, risk assessment, and regulatory reporting — achieve an “appropriate level of accuracy” before they may be deployed. A 2025 legal-technical analysis published on arXiv noted that this requirement embeds critical choices about what errors are acceptable and which risks are prioritised, choices that cannot be made without understanding the specific domain the AI is operating in. (Source: Is your AI Model Accurate Enough? The Difficult Choices Behind Rigorous AI Development and the EU AI Act, arXiv, 2025: arxiv.org)
What AI experts say: the hallucination problem
The AI research community has a name for what happens when a system produces a confident, plausible-sounding output that is factually wrong: hallucination. The term is often used loosely, but the mechanism is precise and well-documented, and matters especially in financial and regulatory contexts.
A language model does not look up facts the way a search engine retrieves documents. It generates responses by predicting what text statistically belongs after a given input, based on patterns learned from vast amounts of training data. When it encounters a question it cannot answer with certainty — because the document is complex, the terminology is ambiguous, or the regulatory framework is specialised — it does not say “I do not know.” It generates the most probable-sounding answer, which may have no basis in the source document at all.
The regulators are paying attention. FINRA’s 2026 Regulatory Oversight Report included a dedicated section on generative AI, explicitly urging financial firms to build procedures that detect hallucinations, defined as instances where AI generates inaccurate or misleading information, including misinterpretations of rules, policies, or client data that influence decision-making. (Source: wealthmanagement.com)
The EU AI Act reinforces this at the structural level. For high-risk AI systems. which include AI applied to credit decisions, risk assessment, and regulatory reporting, Article 14 requires demonstrable human oversight: documented, technically enforced, and auditable.
What makes hallucination particularly dangerous in compliance is that it is often invisible without a traceability mechanism. An incorrect Green Asset Ratio figure, a misattributed Scope 3 emissions value, or a wrongly mapped taxonomy indicator may look exactly right until someone checks the source. And in a post-CRR3 environment, where Pillar 3 disclosures are published to the EBA’s public Data Hub in XBRL format and are cross-referenceable by supervisors and market participants in real time, the cost of an undetected error is not internal. It is public.
The accuracy gap between general-purpose and domain-optimised AI
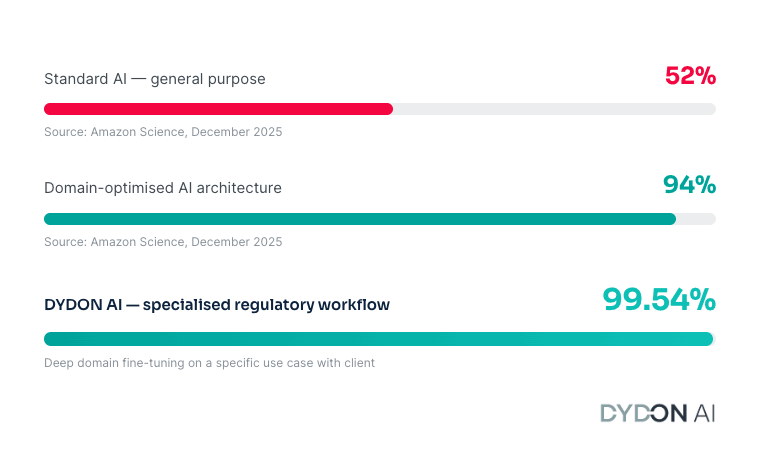
The accuracy gap between a standard AI tool and one built specifically for a specific topic or application is not a small technical detail. Research published by Amazon Science in December 2025 tested different AI systems on the same financial documents — annual reports, financial statements, regulatory filings — and asked them the same questions.
A standard AI system, the kind that powers most general-purpose tools on the market today, answered correctly 52% of the time. An AI system built with financial domain knowledge embedded in its core answered correctly 94% of the time.
Same documents. Same questions. Nearly double the accuracy. (Source: Amazon Science, December 2025: amazon.science)
What explains that gap? Not processing speed. Not the size of the model. The difference comes down to one thing: whether the system actually understands what it is reading.
A standard AI reads a regulatory document the way someone with no financial background would read a tax code. The words are recognisable, the sentences parse correctly, and a summary might even sound convincing. But the understanding of what those words mean in context — which figures apply to which regulatory framework, which qualifications change the meaning of a number, which two differently-worded sentences are actually saying the same thing — is missing. So the system fills the gap with its best guess. And roughly half the time, that guess is wrong.
As the Amazon Science researchers put it: “By integrating financial domain expertise directly into the reasoning process, [a domain-optimised system] offers a practical pathway toward trustworthy financial AI that meets the stringent accuracy demands of regulatory compliance, investment decisions, and risk management.”
To make this concrete: if a compliance team uses a standard AI tool to process 200 data points for a Pillar 3 submission, approximately 96 of those outputs will contain errors. With a domain-optimised system, that number drops to around 12 — and those 12 are flagged for human review rather than passed through silently. That is not a marginal efficiency difference. It is the difference between a process that creates risk and one that controls it.
Real-world validation: We at DYDON AI recently delivered a 99.54% accuracy rate for a client in a specialised regulatory reporting workflow, the result of deep domain fine-tuning on specific data and documents combined with multi-model architecture and full source traceability.
The human expertise: the real source of domain knowledge
High accuracy does not come from technology alone. The domain knowledge embedded in a well-designed compliance AI was built by people, regulatory specialists who understand what a correct answer looks like and why an incorrect one is dangerous. That expertise does not end at deployment. It remains active in the workflow as the validation layer that makes outputs auditable.
The division is straightforward: AI handles volume, humans handle judgment. McKinsey describes this as a risk intelligence function that “serves all lines of defence, automating reporting and improving transparency while risk managers retain decision authority.” (Source: McKinsey)
KPMG has documented up to 85% reduction in reporting preparation time where AI-assisted extraction is fully integrated. EY cites up to 90% time savings in compliance verification with end-to-end AI pre-filling. Those gains depend entirely on one condition: the human validation step must be built into the architecture from the start, not added afterwards.
What to require from an AI compliance platform
These are not differentiating features. They are baselines.
- Full source traceability. Every extracted value must link to its source document, page, and passage. Without this, outputs can only be trusted, not verified.
- Regulatory domain knowledge built in. Embedded knowledge of CRR3, SFDR, EU Taxonomy, and ESRS built by people who work in this space and maintained as frameworks evolve.
- Human validation by design. The EU AI Act’s Article 14 requires auditable human oversight for high-risk AI.
- EU data residency and security. Client-isolated infrastructure, Zero Data Retention guarantees, ISO 27001 and SOC 2 Type II certification. For institutions processing counterparty data and internal capital models, this is a regulatory baseline.
Working in regulatory reporting, ESG disclosure, or compliance and want to understand what accuracy rates are realistic for your specific use case?
Share your workflow with us, we’ll assess what is achievable and where the current gaps in your process are likely to be.
Get in touch →
Sources
- Amazon Science (December 2025). VERAFI: Verified Agentic Financial Intelligence. amazon.science
- Google DeepMind (December 2025). FACTS Leaderboard: A Comprehensive Benchmark for LLM Factuality. deepmind.google
- arXiv (2025). Is your AI Model Accurate Enough? The EU AI Act and AI Accuracy. arxiv.org
- Aveni (December 2025). AI Hallucinations in Financial Services. aveni.ai
- FINRA (2026). 2026 Annual Regulatory Oversight Report. wealthmanagement.com
- McKinsey & Company (2024). How Generative AI Can Help Banks Manage Risk and Compliance. mckinsey.com
- Galileo AI (2025). Domain-Specific LLM Evaluation. galileo.ai
- EBA (September 2025). Rising Application of AI in EU Banking and Payments Sector. eba.europa.eu
- KPMG (2023). Regulatory Technology Report — Automated Regulatory Reporting.
- EY (2023). Global Risk Consulting — Compliance Verification Automation.