
_Summary
ESG questionnaires have become a standard instrument of regulatory compliance across financial services, supply chains, and corporate governance. Banks send them to borrowers. Asset managers send them to fund managers. Corporates receive them from OEMs and downstream customers. Certification bodies distribute them to hundreds of companies simultaneously.
Behind every completed ESG questionnaire is a data collection exercise: pulling figures from sustainability reports, extracting indicators from annual disclosures, cross-referencing PDFs across multiple documents, often in multiple languages, with no two sources formatted the same way. For organizations managing this process at scale, the operational burden is substantial. And the numbers confirm it.
Manual data extraction: this is the scale of the problem
The European Sustainability Reporting Standards (ESRS), the mandatory reporting framework under CSRD, require companies to manage over 1,100 data points across 12 standards, covering everything from climate targets to supply chain labour practices. According to PwC UK’s CSRD guidance, companies face “a complex web of disclosure demands with over 1,000 data points to report on, across 10 key ESG topics.” This is not a reporting exercise confined to a sustainability team. PwC’s Global CSRD Survey (2024), conducted with 547 executives across 30+ countries, found that on average eight business functions are involved in CSRD implementation — including Finance, Operations, Procurement, Legal, and IT — making data collection a cross-organizational challenge that few institutions are structurally equipped to handle efficiently.
The scale of unpreparedness is striking. Despite years of lead time, the same PwC survey found that only 30% of companies had completed an EU Taxonomy analysis, and only 29% had finished a disclosure gap analysis at the time of reporting. A separate analysis published by Council Fire (January 2026) found that 83% of companies find collecting accurate CSRD data significantly challenging, and 29% feel unprepared for ESG data audits.
Meanwhile, market pressure continues to intensify regardless of regulatory timelines. A joint survey by Deloitte and the Fletcher School at Tufts University (2024) found that 83% of investors now include sustainability information in core investment decisions. PwC’s inaugural Global Sustainability Reporting Survey (2025), based on responses from 496 companies across 40 countries, found that an equal share of respondents plan to report on the original timeline even where not legally required to do so — driven by investor and stakeholder expectations rather than regulatory obligation alone. The data burden is arriving regardless of when the regulation formally applies.
The data collection bottleneck nobody talks about
When organizations discuss ESG data challenges, the conversation typically centers on data gaps, comparability issues, or regulatory interpretation. What receives less attention is the upstream problem: getting the data out of documents and into a system where it can actually be used.
Consider the workflow of a certification body running ESG assessments for financial institutions. It sends questionnaires to hundreds of companies. Each company returns documents (sustainability reports, financial statements, internal assessments, third-party audits) alongside partially completed questionnaire responses. A team then reviews each document, locates the relevant data points, verifies consistency with the questionnaire fields, and manually enters or corrects the values.
This process is slow, expensive, and prone to transcription errors. It does not scale. Organizations with integrated systems report up to 70% time savings on ESG data collection compared to manual approaches, according to a January 2026 industry guide on ESG questionnaires. As CSRD extends mandatory disclosure further across the value chain — requiring large companies to collect ESG data from suppliers and counterparties even where those entities are not themselves directly in scope — the volume of incoming documentation is set to increase dramatically.
The same bottleneck exists in different forms across every segment of the market:
- Family offices receiving ESG reports, fund factsheets, and LP disclosures from hundreds of investees
- ESG rating agencies and certification bodies aggregating data from client portfolios at scale
- Large manufacturers required to document supply chain due diligence under LkSG and CSDDD, both sending and receiving compliance documentation
- Banks conducting GAR calculations and SFDR disclosures that require counterparty-level ESG data
In each case, the underlying challenge is identical: structured data required for compliance workflows is locked inside unstructured documents, and extracting it manually is no longer viable at the volumes now required.
BCG’s 2025 global compliance benchmark study found that leading banks are transforming their compliance functions from cost centers into strategic enablers, with AI and generative AI identified as the key lever for managing expanding obligations without proportional headcount growth. The study noted that compliance operating costs have risen sharply in Europe following a wave of new directives — the EU AML package, EBA guidelines, the EU AI Act — all arriving within a 12-month period.
What AI-powered pre-filling actually does
Intelligent Document Processing (IDP) combined with automatic questionnaire answering addresses this problem at its source. The process works in three stages.
Ingestion and parsing
The AI platform receives incoming documents (PDFs, Word files, Excel exports, financial reports, sustainability reports) and processes them regardless of format or structure. Unlike traditional OCR, which simply converts images of text into machine-readable characters, modern AI applies semantic understanding: it reads the document the way an analyst would, identifying document type, applicable reporting framework, and how its content maps to known regulatory and compliance categories.
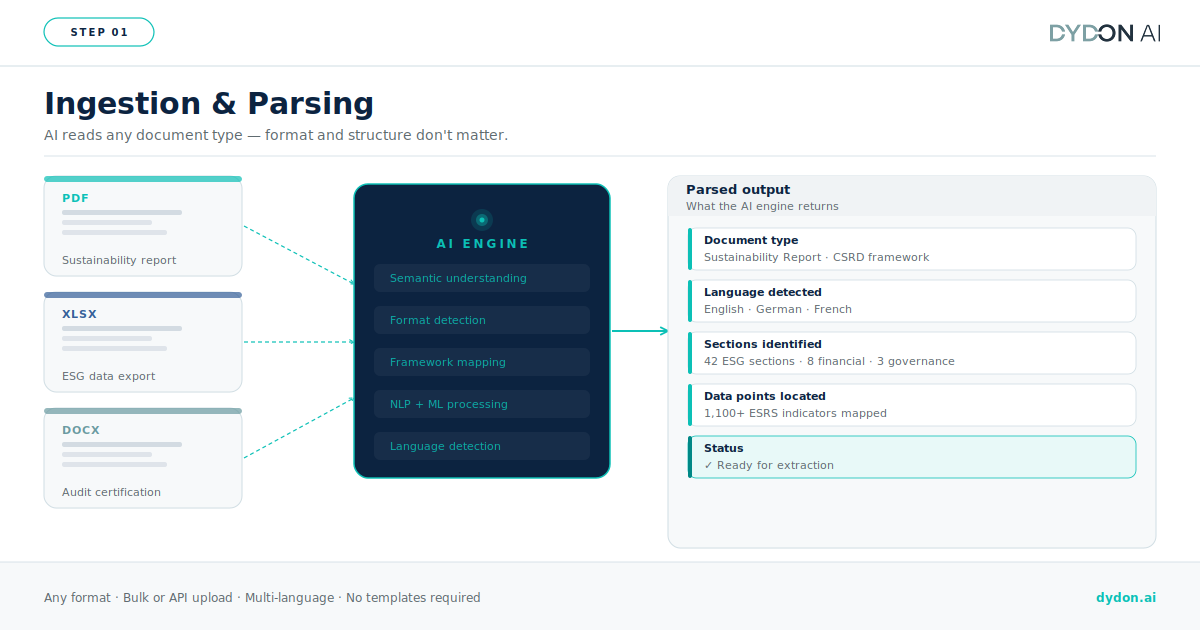
Semantic extraction and categorization
The AI identifies and extracts relevant data points (emissions figures, governance indicators, due diligence disclosures, financial metrics) and categorizes them by domain: ESG, financial, regulatory, or sector-specific. This categorization is not keyword-based. The system recognizes that “Scope 3 indirect emissions” and “value chain carbon footprint” refer to the same indicator, even when terminology varies across documents or languages. Critically, every extracted value is linked to its source — the document, the section, the exact passage — creating a traceable evidence chain for each data point.
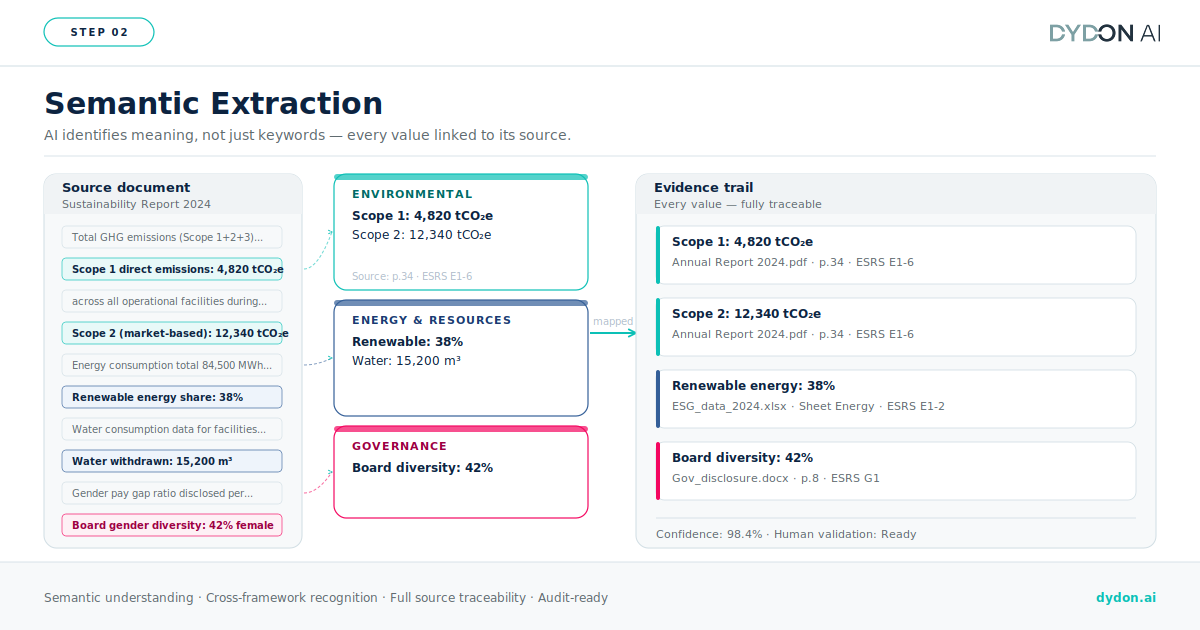
Questionnaire mapping and pre-fill
Extracted data is matched to the corresponding fields in the questionnaire. Where data exists in source documents with sufficient confidence, fields are pre-populated automatically. Where data is missing, ambiguous, or falls below a confidence threshold, the system flags the gap for human review. The output is a partially or substantially completed questionnaire, with each answer accompanied by its source reference, ready for expert validation rather than manual construction.
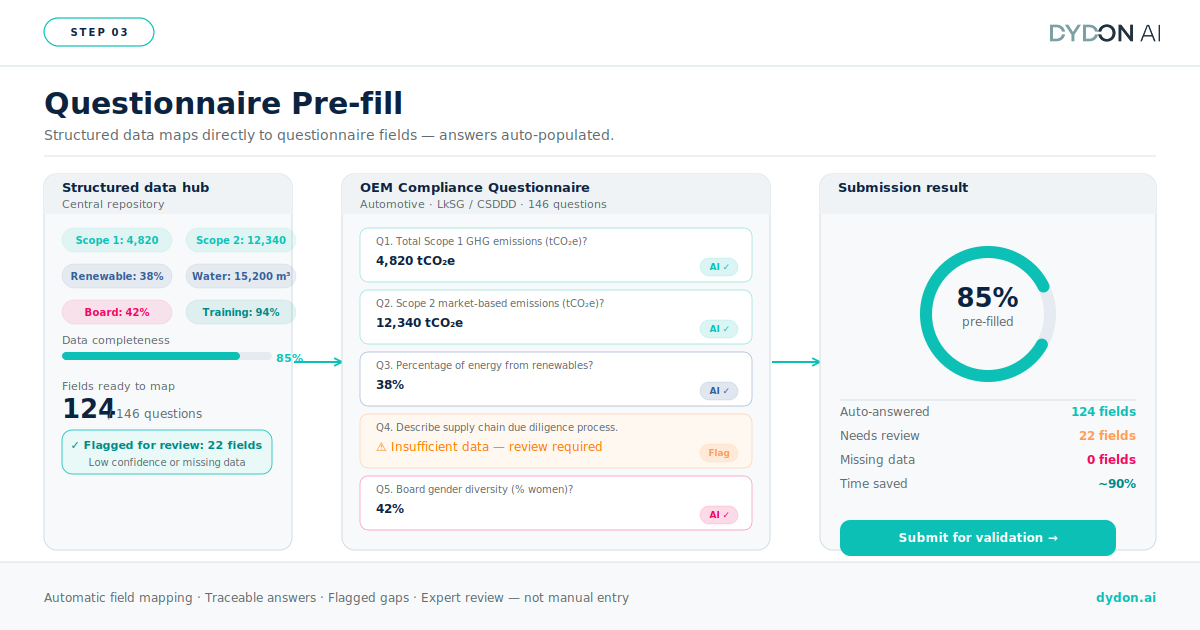
Your ESG and compliance team remains in the loop, but the nature of the work changes fundamentally. Instead of extracting data from documents, the expert validates data that has already been extracted and organized. This is a faster, more accurate, and more defensible process.
In practice: 3 contexts where AI pre-filling applies
ESG certification bodies and data aggregators
Organizations that assess, certify, or aggregate ESG performance on behalf of financial institutions are running data collection operations at industrial scale. The market is recognizing this: the data collection layer is becoming a competitive differentiator, not merely a back-office function — and the organizations that automate it first will process more clients, with greater accuracy, at lower cost per assessment.
This is precisely the use case Dydon AI’s Intelligent Document Processing module was designed to serve. The platform ingests incoming client documents, regardless of format, or reporting framework, extracts the relevant ESG and regulatory data points semantically, and maps them directly to the corresponding questionnaire fields. For certification bodies managing hundreds of client assessments simultaneously, this transforms the review function from one of extraction to one of validation: experts spend their time on judgment, not on copy-paste.
Family offices and asset managers
Family offices receive a continuous stream of documents from investees: fund reports, annual accounts, ESG disclosures, regulatory filings, LP updates. Today, relevant data points are typically extracted manually or not extracted at all, leaving valuable compliance and risk information dormant in a document archive.
Under SFDR, asset managers are required to disclose at entity and product level on a range of principal adverse impact indicators, many of which require counterparty-level data that arrives in document form. AI document processing transforms this archive into a structured, queryable data layer, feeding ESG questionnaires, regulatory disclosures, and internal risk workflows from a single extraction pipeline. The same data set that answers a due diligence questionnaire can also feed an SFDR product disclosure or a client sustainability report, without any duplicate data entry.
Supply chain compliance under LkSG and CSDDD
Manufacturers, energy companies, and infrastructure groups face compliance obligations on two fronts simultaneously. They receive compliance questionnaires from OEM customers and downstream buyers. And they must collect equivalent documentation from their own suppliers to demonstrate supply chain oversight under the German Supply Chain Due Diligence Act (LkSG) and the EU Corporate Sustainability Due Diligence Directive (CSDDD).
As Deloitte has noted in its CSRD FAQ, companies not directly within CSRD scope may nonetheless be affected through their customer and supplier relationships: a private supplier to a CSRD-obligated company may be required to provide emissions data to enable Scope 3 disclosures upstream. This value chain cascade means the questionnaire burden extends far beyond the directly regulated entities. AI document processing handles the extraction layer in both directions — feeding pre-filled questionnaires upstream and downstream in the supply chain, and building the structured evidence base required for audit.
The Omnibus simplification package, finalized in December 2025 as Directive 2026/47, narrows the formal scope of CSRD and CSDDD to the largest companies. But as Latham & Watkins noted in their April 2026 analysis, the double materiality principle is retained in full, and large companies remain obligated to report on value chain impacts — meaning supply chain data collection requirements are structural, not contingent on the regulatory perimeter shifting.
What ESG and compliance teams should look for
AI pre-filling of ESG questionnaires does not operate as a black box, nor should it. Several conditions determine whether the technology delivers accurate, audit-ready results.
Semantic understanding, not pattern matching
ESG and regulatory documents do not follow a single standard structure. A system that relies on positional extraction, finding data at a fixed location in a fixed template, will fail as soon as the document format changes. Robust pre-filling requires AI that understands meaning, not just layout. As Manifest Climate (February 2026) points out, different frameworks — GRI, SASB, TCFD, ESRS — emphasize different aspects and use distinct terminology, creating alignment challenges that keyword-based systems cannot resolve.
Domain-specific training and regulatory knowledge
General-purpose document AI performs inconsistently on regulatory content. The system needs to understand the specific frameworks — CSRD, EU Taxonomy, SFDR, LkSG, CSDDD — well enough to recognize how different documents reference the same indicators under different terminologies, and to flag where regulatory interpretation introduces ambiguity rather than presenting uncertain answers with false confidence.
Full traceability
In a compliance context, an answer without a source is not an answer. Every pre-filled value must be traceable to its origin: the document, the page, the passage. The World Economic Forum has warned that without standardized assurance frameworks, ESG data risks being viewed as less credible than financial data. Traceability is the foundation of that credibility — and it is increasingly expected by auditors and regulators alike.
Human validation architecture
Pre-filling is not a replacement for expert review. It is a tool that makes expert review faster and more focused. The platform must be designed to support this, surfacing low-confidence extractions, flagging missing data, and presenting evidence for each value in a format that allows rapid validation by a compliance professional.
Data security and isolation
ESG questionnaires frequently contain commercially sensitive and legally protected information. AI processing of this data must occur in a secure, client-isolated environment. Data cannot flow into shared models or be used for training purposes. For European organizations, data residency within the EU is a baseline requirement, not an optional safeguard. PwC’s ESG data collection guidance reinforces this point, noting that companies will increasingly need to validate ESG data from source to report under emerging audit and attestation requirements.
All of this, in a single AI platform for your compliance team
Dydon AI’s regulatory intelligence platform is built to meet all five requirements: semantic extraction, regulatory domain knowledge, full traceability, human validation workflows, and client-isolated European infrastructure. Every document stays in your environment. Every extracted value links back to its source.
Because every organization’s compliance landscape is different, we offer a free expert consultation to audit your specific situation: where the extraction burden is highest, where automation generates the most immediate value, and how it integrates with your existing workflows. Talk to our experts and find out what this looks like for your organisation.
From document chaos to structured intelligence
The ESG questionnaire is, ultimately, a structured data collection instrument. Its purpose is to aggregate comparable, verifiable information across organizations, frameworks, and reporting periods. The irony is that the data it seeks is already available: sitting in sustainability reports, annual accounts, and regulatory filings, but locked in a format that requires significant manual effort to unlock.
AI-powered pre-filling closes that gap. It does not make ESG assessment easier by lowering the bar. It makes ESG data collection faster by eliminating the most time-consuming part of the process: the extraction. The result is compliance teams that spend their time assessing, validating, and deciding — rather than reading, copying, and entering. At scale, across hundreds of documents and dozens of questionnaires, this represents a qualitative shift in what compliance operations can realistically achieve.
As BCG concluded in its 2025 compliance benchmark study, the most effective compliance teams of the future will be those that skillfully combine risk and operations expertise with advanced technological capabilities. Pre-filling ESG questionnaires with AI is not the end state — it is one concrete, deployable step in that direction, available now.
Dydon AI’s Intelligent Document Processing module automatically extracts, structures, and categorizes data from regulatory and ESG documents, feeding directly into the Automatic Questionnaire Answering workflow. Every extracted value is traceable to its source. All data is processed in a secure, client-isolated European infrastructure. Talk to our experts →