
_Zusammenfassung
ESG-Fragebögen sind zu einem Standardinstrument für die Einhaltung gesetzlicher Vorschriften in den Bereichen Finanzdienstleistungen, Lieferketten und Unternehmensführung geworden. Banken versenden sie an Kreditnehmer. Vermögensverwalter senden sie an Fondsmanager. Unternehmen erhalten sie von Erstausrüstern und nachgelagerten Kunden. Zertifizierungsstellen versenden sie gleichzeitig an Hunderte von Unternehmen.
Hinter jedem ausgefüllten ESG-Fragebogen steht ein aufwendiger Datenerfassungsprozess: Zahlen aus Nachhaltigkeitsberichten zusammenstellen, Kennzahlen aus Jahresberichten extrahieren, PDF-Dateien über mehrere Dokumente hinweg abgleichen – oft in verschiedenen Sprachen und wobei keine zwei Quellen gleich formatiert sind. Für Unternehmen, die diesen Prozess in großem Umfang bewältigen müssen, ist der operative Aufwand enorm. Und die Zahlen bestätigen dies.
Manuelle Datenextraktion: Das ist das Ausmaß des Problems
Die European Sustainability Reporting Standards (ESRS), das verbindliche Berichtsrahmenwerk im Rahmen der CSRD, verlangen von Unternehmen die Verwaltung von über 1.100 Datenpunkten in 12 Standards, die alles von Klimazielen bis hin zu Arbeitspraktiken in der Lieferkette abdecken. Laut dem CSRD-Leitfaden von PwC UK sehen sich Unternehmen „einem komplexen Geflecht von Offenlegungsanforderungen mit über 1.000 zu berichtenden Datenpunkten in 10 zentralen ESG-Themenbereichen“ gegenüber. Dies ist keine Berichterstattungsaufgabe, die sich auf ein Nachhaltigkeitsteam beschränkt. Die von PwC durchgeführte globale CSRD-Umfrage (2024), an der 547 Führungskräfte aus über 30 Ländern teilnahmen, ergab, dass durchschnittlich acht Unternehmensbereiche an der Umsetzung der CSRD beteiligt sind – darunter Finanzen, Betrieb, Beschaffung, Recht und IT –, was die Datenerhebung zu einer organisationsübergreifenden Herausforderung macht, für deren effiziente Bewältigung nur wenige Institutionen strukturell gerüstet sind.
Das Ausmaß der Unvorbereitetheit ist frappierend. Trotz jahrelanger Vorlaufzeit ergab dieselbe PwC-Umfrage, dass zum Zeitpunkt der Berichterstattung nur 30 % der Unternehmen eine EU-Taxonomie-Analyse abgeschlossen hatten und nur 29 % eine Analyse der Offenlegungslücken durchgeführt hatten. Eine separate Analyse von Council Fire (Januar 2026) ergab, dass 83 % der Unternehmen die Erhebung genauer CSRD-Daten als erhebliche Herausforderung empfinden und 29 % sich auf ESG-Datenprüfungen nicht vorbereitet fühlen.
Unterdessen nimmt der Marktdruck ungeachtet der regulatorischen Fristen weiter zu. Eine gemeinsame Umfrage von Deloitte und der Fletcher School der Tufts University (2024) ergab, dass 83 % der Investoren Nachhaltigkeitsinformationen mittlerweile in ihre zentralen Anlageentscheidungen einbeziehen. Die erste „Global Sustainability Reporting Survey“ (2025) von PwC, die auf Antworten von 496 Unternehmen aus 40 Ländern basiert, ergab, dass ein gleich großer Anteil der Befragten plant, bereits nach dem ursprünglichen Zeitplan zu berichten, selbst wenn dies gesetzlich nicht vorgeschrieben ist – getrieben eher von den Erwartungen der Investoren und Stakeholder als von rein regulatorischen Verpflichtungen. Der Datenaufwand entsteht unabhängig davon, wann die Verordnung offiziell in Kraft tritt.
Der Engpass bei der Datenerfassung, über den niemand spricht
Wenn Unternehmen über Herausforderungen im Zusammenhang mit ESG-Daten sprechen, dreht sich die Diskussion in der Regel um Datenlücken, Probleme bei der Vergleichbarkeit oder die Auslegung gesetzlicher Vorschriften. Weniger Beachtung findet dabei das vorgelagerte Problem: die Daten aus den Dokumenten zu extrahieren und in ein System zu übertragen, wo sie tatsächlich genutzt werden können.
Betrachten wir den Arbeitsablauf einer Zertifizierungsstelle, die ESG-Bewertungen für Finanzinstitute durchführt. Das Unternehmen versendet Fragebögen an Hunderte von Unternehmen. Jedes Unternehmen sendet neben teilweise ausgefüllten Fragebogenantworten auch Dokumente (Nachhaltigkeitsberichte, Jahresabschlüsse, interne Bewertungen, Audits durch Dritte) zurück. Ein Team prüft daraufhin jedes Dokument, ermittelt die relevanten Datenpunkte, überprüft die Übereinstimmung mit den Fragebogenfeldern und gibt die Werte manuell ein oder korrigiert sie.
Dieser Prozess ist langsam, kostspielig und anfällig für Übertragungsfehler. Er ist nicht skalierbar. Unternehmen mit integrierten Systemen berichten laut einem Branchenleitfaden zu ESG-Fragebögen vom Januar 2026 von bis zu 70 % Zeiteinsparungen bei der ESG-Datenerhebung im Vergleich zu manuellen Verfahren. Da die CSRD die Offenlegungspflicht weiter auf die gesamte Wertschöpfungskette ausweitet – und große Unternehmen dazu verpflichtet, ESG-Daten von Lieferanten und Geschäftspartnern zu erheben, selbst wenn diese Unternehmen selbst nicht direkt in den Anwendungsbereich fallen –, wird das Volumen der eingehenden Unterlagen voraussichtlich dramatisch ansteigen.
Derselbe Engpass tritt in unterschiedlicher Form in jedem Marktsegment auf:
- Family Offices, die ESG-Berichte, Fondsdatenblätter und Informationen für Kommanditisten von Hunderten von Portfoliounternehmen erhalten
- ESG-Ratingagenturen und Zertifizierungsstellen, die Daten aus Kundenportfolios in großem Umfang zusammenführen
- Große Hersteller sind gemäß LkSG und CSDDD verpflichtet, die Sorgfaltspflichten in der Lieferkette zu dokumentieren und sowohl die entsprechenden Unterlagen zu übermitteln als auch entgegenzunehmen
- Banken, die GAR-Berechnungen und SFDR-Offenlegungen durchführen, für die ESG-Daten auf Gegenparteiebene erforderlich sind
In jedem Fall ist die zugrunde liegende Herausforderung dieselbe: Die für Compliance-Workflows benötigten strukturierten Daten sind in unstrukturierten Dokumenten eingeschlossen, und eine manuelle Extraktion ist angesichts des mittlerweile erforderlichen Datenvolumens nicht mehr praktikabel.
Die globale Compliance-Benchmark-Studie 2025 von BCG ergab, dass führende Banken ihre Compliance-Funktionen von Kostenstellen in strategische Wegbereiter umwandeln, wobei KI und generative KI als entscheidender Hebel identifiziert wurden, um die wachsenden Verpflichtungen ohne einen entsprechenden Personalzuwachs zu bewältigen. Die Studie stellte fest, dass die Betriebskosten für Compliance in Europa infolge einer Welle neuer Richtlinien – des EU-AML-Pakets, der EBA-Leitlinien und des EU-KI-Gesetzes –, die alle innerhalb eines Zeitraums von zwölf Monaten in Kraft traten, stark angestiegen sind.
Was die KI-gestützte Vorausfüllung tatsächlich bewirkt
Die intelligente Dokumentenverarbeitung (IDP) in Verbindung mit der automatischen Beantwortung von Fragebögen geht dieses Problem an der Wurzel an. Der Prozess läuft in drei Schritten ab.
Einlesen und Verarbeiten
Die KI-Plattform nimmt eingehende Dokumente (PDFs, Word-Dateien, Excel-Exporte, Finanzberichte, Nachhaltigkeitsberichte) entgegen und verarbeitet sie unabhängig von Format oder Struktur. Im Gegensatz zu herkömmlicher OCR, die lediglich Textbilder in maschinenlesbare Zeichen umwandelt, nutzt moderne KI semantisches Verständnis: Sie liest das Dokument so, wie es ein Analyst tun würde, und ermittelt dabei den Dokumenttyp, das geltende Berichtsrahmenwerk sowie die Zuordnung des Inhalts zu bekannten regulatorischen und Compliance-Kategorien.
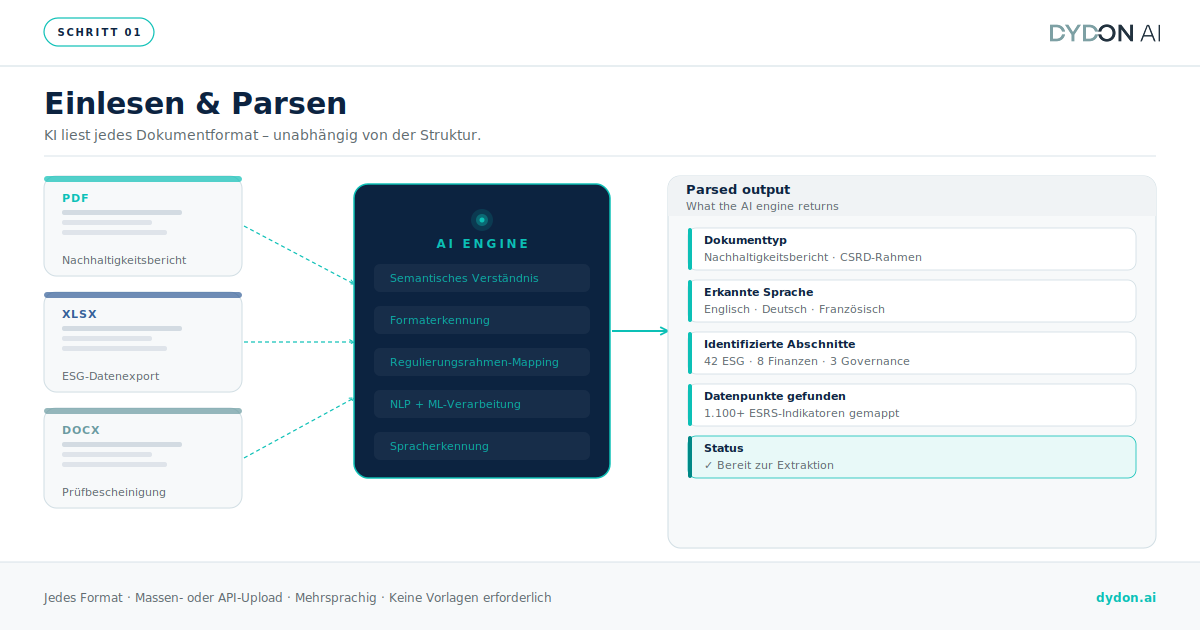
Semantische Extraktion und Kategorisierung
Die KI identifiziert und extrahiert relevante Datenpunkte (Emissionswerte, Governance-Indikatoren, Angaben zur Sorgfaltspflicht, Finanzkennzahlen) und ordnet sie nach Bereichen ein: ESG, Finanzen, Regulierung oder branchenspezifisch. Diese Kategorisierung erfolgt nicht auf Basis von Schlüsselwörtern. Das System erkennt, dass sich „indirekte Scope-3-Emissionen“ und „CO₂-Fußabdruck der Wertschöpfungskette“ auf denselben Indikator beziehen, selbst wenn die Terminologie in verschiedenen Dokumenten oder Sprachen variiert. Entscheidend ist, dass jeder extrahierte Wert mit seiner Quelle verknüpft ist – dem Dokument, dem Abschnitt, der genauen Passage –, wodurch für jeden Datenpunkt eine nachvollziehbare Beweiskette entsteht.
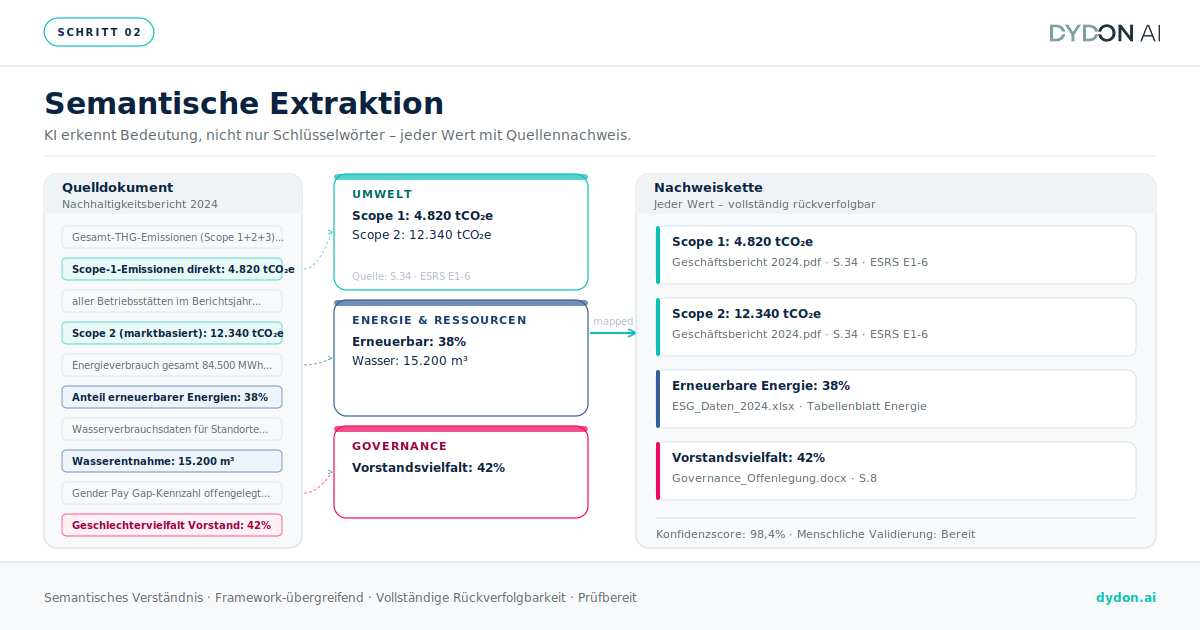
Zuordnung und Vorausfüllung von Fragebögen
Die extrahierten Daten werden den entsprechenden Feldern im Fragebogen zugeordnet. Liegen in den Quelldokumenten Daten mit ausreichender Zuverlässigkeit vor, werden die Felder automatisch vorausgefüllt. Fehlen Daten, sind sie mehrdeutig oder unterschreiten sie einen Zuverlässigkeitsschwellenwert, kennzeichnet das System die Lücke zur manuellen Überprüfung. Das Ergebnis ist ein teilweise oder weitgehend ausgefüllter Fragebogen, bei dem jede Antwort mit einem Quellenverweis versehen ist und somit zur Validierung durch Experten bereitsteht, anstatt manuell erstellt werden zu müssen.
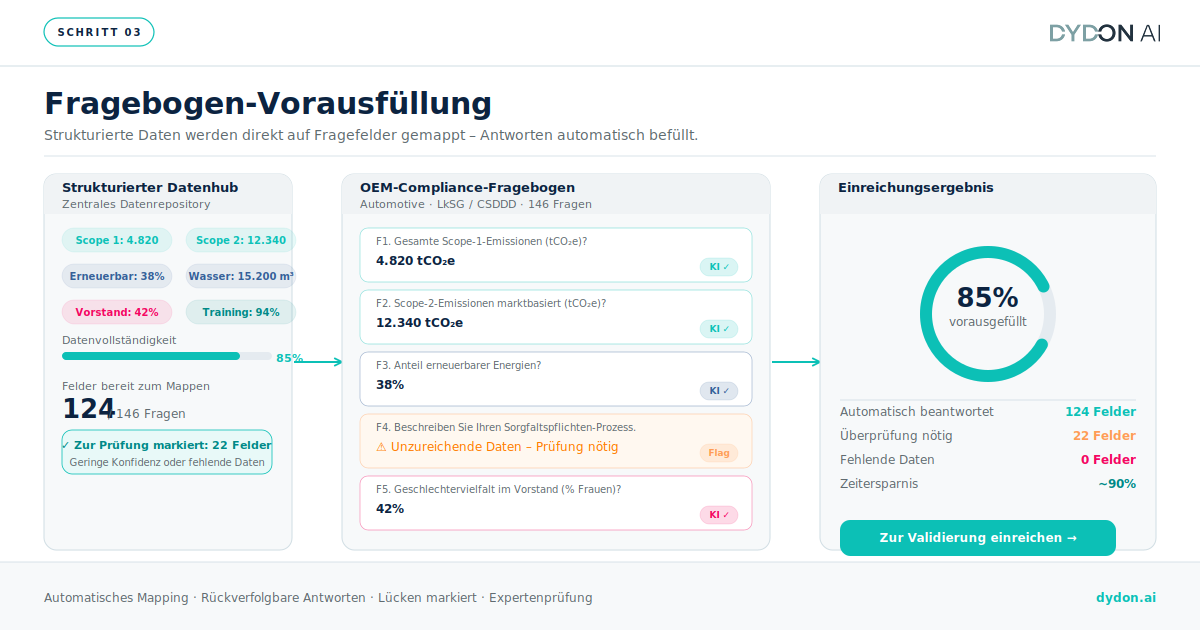
Ihr ESG- und Compliance-Team bleibt weiterhin auf dem Laufenden, doch die Art der Arbeit ändert sich grundlegend. Anstatt Daten aus Dokumenten zu extrahieren, überprüft der Experte Daten, die bereits extrahiert und strukturiert wurden. Dies ist ein schnellerer, genauerer und besser zu rechtfertigender Prozess.
In der Praxis: 3 Anwendungsfälle für das automatische Ausfüllen durch KI
ESG-Zertifizierungsstellen und Datenaggregatoren
Unternehmen, die im Auftrag von Finanzinstituten ESG-Leistungen bewerten, zertifizieren oder aggregieren, betreiben Datenerhebungsprozesse im industriellen Maßstab. Der Markt hat dies erkannt: Die Datenerhebung entwickelt sich zu einem Wettbewerbsvorteil und ist nicht mehr nur eine Backoffice-Funktion – und diejenigen Unternehmen, die diesen Prozess als Erste automatisieren, werden mehr Kunden bedienen können, und zwar mit höherer Genauigkeit und zu geringeren Kosten pro Bewertung.
Genau für diesen Anwendungsfall wurde das Modul „Intelligent Document Processing“ von Dydon AI entwickelt. Die Plattform nimmt eingehende Kundendokumente unabhängig von Format oder Berichtsrahmen auf, extrahiert die relevanten ESG- und regulatorischen Daten semantisch und ordnet sie direkt den entsprechenden Feldern im Fragebogen zu. Für Zertifizierungsstellen, die Hunderte von Kundenbewertungen gleichzeitig verwalten, wandelt dies die Überprüfungsfunktion von einer Extraktions- zu einer Validierungsaufgabe um: Experten widmen ihre Zeit der Beurteilung und nicht dem Kopieren und Einfügen.
Family Offices und Vermögensverwalter
Family Offices erhalten von ihren Portfoliounternehmen einen stetigen Strom an Dokumenten: Fondsberichte, Jahresabschlüsse, ESG-Offenlegungen, behördliche Meldungen und Informationen für Kommanditisten. Heutzutage werden relevante Datenpunkte in der Regel manuell extrahiert oder gar nicht extrahiert, sodass wertvolle Compliance- und Risikoinformationen ungenutzt in einem Dokumentenarchiv schlummern.
Gemäß der SFDR sind Vermögensverwalter verpflichtet, auf Unternehmens- und Produktebene eine Reihe von Indikatoren für wesentliche nachteilige Auswirkungen offenzulegen, von denen viele Daten auf Gegenparteiebene erfordern, die in Form von Dokumenten vorliegen. Die KI-gestützte Dokumentenverarbeitung wandelt dieses Archiv in eine strukturierte, abfragbare Datenebene um und versorgt ESG-Fragebögen, aufsichtsrechtliche Offenlegungen und interne Risikoworkflows über eine einzige Extraktionspipeline. Derselbe Datensatz, der einen Due-Diligence-Fragebogen beantwortet, kann auch eine SFDR-Produktangabe oder einen Nachhaltigkeitsbericht für Kunden speisen, ohne dass Daten doppelt eingegeben werden müssen.
Einhaltung der Lieferkettenvorschriften gemäß LkSG und CSDDD
Hersteller, Energieunternehmen und Infrastrukturkonzerne sehen sich gleichzeitig mit Compliance-Verpflichtungen an zwei Fronten konfrontiert. Sie erhalten Compliance-Fragebögen von OEM-Kunden und nachgelagerten Abnehmern. Zudem müssen sie entsprechende Unterlagen von ihren eigenen Lieferanten einholen, um die Kontrolle über die Lieferkette gemäß dem deutschen Lieferketten-Sorgfaltspflichtgesetz (LkSG) und der EU-Richtlinie zur Sorgfaltspflicht von Unternehmen im Bereich der Nachhaltigkeit (CSDDD) nachzuweisen.
Wie Deloitte in seinen CSRD-FAQ feststellt, können Unternehmen, die nicht unmittelbar in den Anwendungsbereich der CSRD fallen, dennoch über ihre Kunden- und Lieferantenbeziehungen betroffen sein: Ein privater Lieferant eines CSRD-pflichtigen Unternehmens kann verpflichtet sein, Emissionsdaten bereitzustellen, um die Offenlegung von Scope-3-Emissionen in vorgelagerten Bereichen zu ermöglichen. Diese Kaskade entlang der Wertschöpfungskette bedeutet, dass sich der Aufwand für die Beantwortung von Fragebögen weit über die unmittelbar regulierten Unternehmen hinaus erstreckt. Die KI-basierte Dokumentenverarbeitung übernimmt die Datenextraktion in beide Richtungen – sie liefert vorgefertigte Fragebögen sowohl vor- als auch nachgelagert in der Lieferkette und erstellt die für die Prüfung erforderliche strukturierte Nachweisdokumentation.
Das im Dezember 2025 als Richtlinie 2026/47 verabschiedete Omnibus-Vereinfachungspaket beschränkt den formellen Anwendungsbereich der CSRD und der CSDDD auf die größten Unternehmen. Wie Latham & Watkins jedoch in ihrer Analyse vom April 2026 feststellte, bleibt das Prinzip der doppelten Wesentlichkeit vollständig erhalten, und große Unternehmen sind weiterhin verpflichtet, über Auswirkungen auf die Wertschöpfungskette zu berichten – was bedeutet, dass die Anforderungen an die Erhebung von Lieferkettendaten struktureller Natur sind und nicht von einer Verschiebung des regulatorischen Anwendungsbereichs abhängen.
Worauf ESG- und Compliance-Teams achten sollten
Das automatische Ausfüllen von ESG-Fragebögen durch KI funktioniert nicht wie eine Blackbox – und das sollte es auch nicht. Es gibt mehrere Faktoren, die darüber entscheiden, ob die Technologie genaue, prüfungsreife Ergebnisse liefert.
Semantisches Verständnis statt Mustererkennung
ESG- und regulatorische Dokumente folgen keiner einheitlichen Standardstruktur. Ein System, das auf Positionserkennung basiert und Daten an einer festen Stelle in einer festen Vorlage findet, versagt, sobald sich das Dokumentformat ändert. Eine robuste Vorausfüllung erfordert KI, die nicht nur das Layout, sondern auch die Bedeutung versteht. Wie Manifest Climate (Februar 2026) hervorhebt, legen verschiedene Rahmenwerke – GRI, SASB, TCFD, ESRS – unterschiedliche Schwerpunkte und verwenden unterschiedliche Terminologie, was zu Abstimmungsproblemen führt, die keywordbasierte Systeme nicht lösen können.
Domain-Specific Training und Regulatorisches Wissen
Allgemeine Dokumenten-KI liefert bei regulatorischen Inhalten uneinheitliche Ergebnisse. Das System muss die spezifischen Rahmenwerke – CSRD, EU-Taxonomie, SFDR, LkSG, CSDDD – gut genug verstehen, um zu erkennen, wie verschiedene Dokumente unter unterschiedlichen Begrifflichkeiten auf dieselben Indikatoren verweisen, und um Fälle zu kennzeichnen, in denen die Auslegung von Vorschriften zu Unklarheiten führt, anstatt mit falscher Sicherheit ungewisse Antworten zu liefern.
Übersetzt mit DeepL.com (kostenlose Version)
Vollständige Rückverfolgbarkeit
Im Hinblick auf die Compliance gilt eine Antwort ohne Quellenangabe nicht als Antwort. Jeder vorab ausgefüllte Wert muss bis zu seiner Quelle zurückverfolgt werden können: dem Dokument, der Seite, der Passage. Das World Economic Forum hat davor gewarnt, dass ESG-Daten ohne standardisierte Rahmenwerke zur Qualitätssicherung Gefahr laufen, als weniger glaubwürdig angesehen zu werden als Finanzdaten. Rückverfolgbarkeit ist die Grundlage dieser Glaubwürdigkeit – und wird sowohl von Wirtschaftsprüfern als auch von Aufsichtsbehörden zunehmend erwartet.
Architektur zur Überprüfung durch Menschen
Das Vorausfüllen ist kein Ersatz für die Überprüfung durch einen Experten. Es ist ein Hilfsmittel, das die Überprüfung durch einen Experten beschleunigt und zielgerichteter gestaltet. Die Plattform muss so konzipiert sein, dass sie dies unterstützt, indem sie Auszüge mit geringer Zuverlässigkeit hervorhebt, fehlende Daten kennzeichnet und für jeden Wert Belege in einem Format bereitstellt, das eine schnelle Überprüfung durch einen Compliance-Experten ermöglicht.
Datensicherheit und Isolierung
ESG-Fragebögen enthalten häufig geschäftlich sensible und rechtlich geschützte Informationen. Die KI-Verarbeitung dieser Daten muss in einer sicheren, kundenisolierten Umgebung erfolgen. Die Daten dürfen nicht in gemeinsam genutzte Modelle einfließen oder zu Trainingszwecken verwendet werden. Für europäische Organisationen ist die Datenresidenz innerhalb der EU eine Grundvoraussetzung und keine optionale Sicherheitsmaßnahme. Die Leitlinien von PwC zur ESG-Datenerhebung unterstreichen diesen Punkt und weisen darauf hin, dass Unternehmen ESG-Daten zunehmend von der Quelle bis zur Berichterstattung validieren müssen, um den neuen Anforderungen an die Prüfung und Bescheinigung gerecht zu werden.
All das in einer einzigen KI-Plattform für Ihr Compliance-Team
Die Regulatory-Intelligence-Plattform von Dydon AI wurde entwickelt, um alle fünf Anforderungen zu erfüllen: semantische Extraktion, Fachwissen im Bereich der Regulierung, lückenlose Rückverfolgbarkeit, Workflows zur manuellen Validierung sowie eine kundenisolierte Infrastruktur in Europa. Jedes Dokument verbleibt in Ihrer Umgebung. Jeder extrahierte Wert ist mit seiner Quelle verknüpft.
Da die Compliance-Situation in jedem Unternehmen anders ist, bieten wir Ihnen eine kostenlose Beratung durch unsere Experten an, um Ihre spezifische Situation zu analysieren: Wo ist der Aufwand für die Datenextraktion am größten? Wo bringt die Automatisierung den größten unmittelbaren Nutzen? Und wie lässt sie sich in Ihre bestehenden Arbeitsabläufe integrieren? Sprechen Sie mit unseren Experten und finden Sie heraus, wie dies für Ihr Unternehmen aussehen könnte.
Vom Dokumentenchaos zu strukturierten Informationen
Der ESG-Fragebogen ist letztlich ein strukturiertes Instrument zur Datenerhebung. Sein Zweck besteht darin, vergleichbare und überprüfbare Informationen über Organisationen, Rahmenwerke und Berichtszeiträume hinweg zusammenzuführen. Die Ironie dabei ist, dass die gesuchten Daten bereits verfügbar sind: Sie finden sich in Nachhaltigkeitsberichten, Jahresabschlüssen und behördlichen Unterlagen, sind jedoch in einem Format gespeichert, dessen Auswertung einen erheblichen manuellen Aufwand erfordert.
Die KI-gestützte Vorausfüllung schließt diese Lücke. Sie vereinfacht die ESG-Bewertung nicht, indem sie die Anforderungen senkt. Sie beschleunigt die Erfassung von ESG-Daten, indem sie den zeitaufwendigsten Teil des Prozesses eliminiert: die Datenextraktion. Das Ergebnis sind Compliance-Teams, die ihre Zeit mit der Bewertung, Validierung und Entscheidungsfindung verbringen – statt mit Lesen, Kopieren und Eingeben. Bei großem Umfang, über Hunderte von Dokumenten und Dutzende von Fragebögen hinweg, bedeutet dies eine qualitative Veränderung dessen, was Compliance-Abteilungen realistisch erreichen können.
Wie BCG in seiner Compliance-Benchmark-Studie für 2025 feststellte, werden die effektivsten Compliance-Teams der Zukunft diejenigen sein, die Fachwissen in den Bereichen Risiko und Betriebsabläufe gekonnt mit fortschrittlichen technologischen Fähigkeiten verbinden. Das Vorausfüllen von ESG-Fragebögen mithilfe von KI ist nicht das Endziel – es ist ein konkreter, umsetzbarer Schritt in diese Richtung, der bereits heute verfügbar ist.
Das Modul „Intelligente Dokumentenverarbeitung“ von Dydon AI extrahiert, strukturiert und kategorisiert automatisch Daten aus regulatorischen und ESG-Dokumenten und speist diese direkt in den Workflow zur automatischen Beantwortung von Fragebögen ein. Jeder extrahierte Wert ist bis zu seiner Quelle zurückverfolgbar. Alle Daten werden in einer sicheren, kundenisolierten Infrastruktur in Europa verarbeitet. Sprechen Sie mit unseren Experten →